TAAC七日游
TAAC比赛的参赛记录
TAAC七日游#
本文记录了我在TAAC(腾讯广告算法大赛)比赛中的参赛经历和心得体会。
2025年7月31日,在比赛报名截止的六小时前本人于一个交流群中得知了TAAC比赛,并决定报名参加。
7.31 报名&搜集一些基础信息#
一文读懂算法大赛前沿赛题 ↗ 介绍了数据集形式、基线模型的思路、优化升级思路、embedding分析工具。
基本上有价值的信息都在这三篇文章中。以及主办方提供了三篇论文作为参考。
A Review of Modern Recommender Systems Using Generative Models (Gen-RecSys)#
第一篇是个综述,使用苏剑林老师的papers.cool网站进行检索和快速阅读 ↗
这篇综述将现代生成式推荐系统(Gen-RecSys)分为三大类模型:
- 仅依赖用户-物品交互的模型:如 VAE-CF、BERT4Rec、SASRec、IRGAN、DiffRec、GFN4Rec 等。
- 以文本为核心的 LLM 驱动模型:包括用于稠密检索的 BERT/T5、零样本/少样本提示的 GPT 系列、指令微调后的 P5/TALLRec,以及检索增强的 RAG 框架。
- 多模态模型:如 CLIP/ALBEF(图文对比)、ContrastVAE(多模态 VAE)、Stable-Diffusion/DALL-E(图像生成)、以及 LLaVA 等多模态大模型。
未来改进方向集中在:
- 提升 RAG 的多源数据融合与端到端训练
- 设计工具增强的主动对话推荐架构
- 借助扩散模型实现个性化虚拟试穿等内容生成
- 开展对抗红队测试以保证鲁棒性
- 建立兼顾性能、公平、隐私与社会影响的统一评估框架
Recommender Systems with Generative Retrieval#
第二篇论文是谷歌于2023年在NIPS上发表的论文,介绍了一个名为 TIGER 的推荐系统模型。快速阅读 ↗
TIGER 的主要流程如下:
- 编码商品内容:先用 RQ-VAE 把每件商品的内容向量压缩成 4 个离散语义码(Semantic ID)。
- 序列建模:用 Transformer encoder-decoder,将用户的历史商品序列(用这些语义码表示)作为输入,自回归地逐 token 生成下一个商品的语义码。
- 训练与推理:训练时仅做最大似然估计;在线推理时无需 ANN 索引,直接在 Transformer 的 memory 里做 beam search 解码即可获得候选。
后续改进可沿三条主线:
- 效率:改用低秩 KV-cache、前缀树约束或知识蒸馏加速解码。
- 冷启与长尾:将文本/图像等多模态编码器与 RQ-VAE 联合训练,或引入对比学习让未见商品的语义码更具判别性。
- 可控多样性:在层级语义码上加入可学习温度或强化学习奖励,以平衡相关性与新颖性。
Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations#
第三篇论文是Meta于2024年在ICML上发表的论文,介绍了一个名为 HSTU(Hierarchical Sequential Transduction Units) 的推荐系统模型。快速阅读 ↗
这篇论文提出了生成推荐模型(Generative Recommenders, GRs)及其核心编码器 HSTU(Hierarchical Sequential Transduction Units),首次将工业级推荐系统统一建模为序列转换任务。
HSTU 的主要特点如下:
- 结构简化:用单一模块替代传统 DLRM 的“提取-交互-变换”三段式结构。
- 编码方式:先以线性层投影得到 QKV,再用无 softmax 的点积注意力聚合序列信息,最后经 SwiGLU 式门控输出。
- 高效训练:训练中采用“生成式”采样,按 1/|sequence| 的概率抽取用户序列,实现 O(N²) 降为 O(N) 的复杂度。
- 推理优化:通过 Stochastic Length 随机裁剪长序列、M-FALCON 微批次推理与 KV 缓存,在同等 GPU 预算下将推理复杂度摊销 285 倍。
该范式解决了 DLRM 特征工程繁重、算力扩展停滞、长序列难建模三大难题,在线 A/B 提升 12.4%,并首次在推荐领域验证“模型质量随训练算力呈幂律增长”的 Scaling Law。
后续可从以下方向继续改进:
- 更长序列建模
- 实时增量更新
- 隐私保护特征
- 跨域迁移
- 冷启动
- 模型压缩与能耗优化
8.1 赶路 & 补习知识#
今天大部时间花在了从家到学校的路上,利用这个时间以及到学校后的时间补习了一些知识。
本人是推荐系统小白,之前只是听说过协同过滤(CF),但对具体的实现细节并不熟悉。
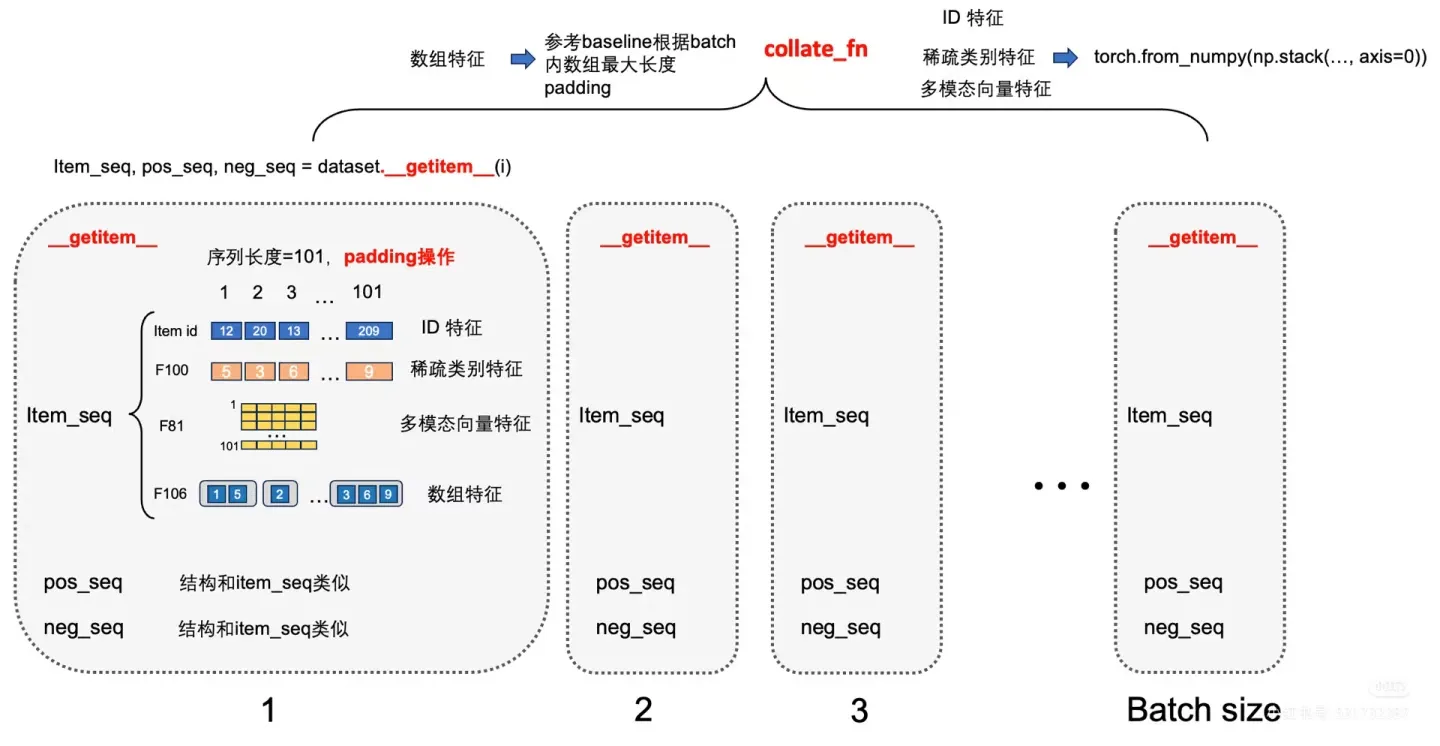
同时今天也开放了比赛平台,下载了数据集和基线模型。然而基线模型只有示例代码(不完整),没有提供预训练模型。
基线模型给出的流程是先使用提供的 RQ-VAE 框架代码将多模态emb数据转换为Semantic Id,参照 Item Sparse 特征格式处理Semantic Id,作为新特征加入Baseline模型训练。这一步是为了处理多模态模型和推荐模型之间巨大的gap。多模态本身难道没有gap吗(笑)
目前并不打算开始跑这套流程,先补习一些推荐系统的基础知识。毕竟之前只学习了VAE,RQ-VAE还并不是很清楚它是怎么做的。RQ-VAE的学习只能放到明天了。
目前来看,比赛流程大致按照一文读懂算法大赛前沿赛题 ↗中提到的进行即可,主要包括数据预处理、模型训练与评估等环节。对于数据的预处理,主要是将多模态数据转换为 Semantic Id,并将其作为新的特征加入到模型中。剩下的模型选取则比较随便了,或许可以使用Muon优化器替代Adam优化器。
全模态生成式推荐系统的核心在于如何将用户的历史行为和商品的特征进行有效的建模,以生成个性化的推荐结果。next token prediction和next item prediction也没有本质上的差别,都是seq2seq任务。只是掺入更多的模态和时序因素会非常难处理。
8.2 RQ-VAE学习#
今天主要学习了 RQ-VAE 的相关知识,了解了其基本原理和实现方式。
对于普通的 VAE 我们假设后验分布是高斯分布,很显然它是连续的,而 RQ-VAE 则假设后验分布是离散的。非常合适用在这里为 embedding 生成离散的语义码(Semantic ID)。仅仅对于离散的语义码,来说 17 年提出的 VQ-VAE(Vector Quantized Variational Autoencoder)方法就足够了。
VQ-VAE 通过引入向量量化(Vector Quantization)技术,将连续的潜在空间离散化,从而实现对离散语义码的建模。
VQ-VAE 详解#
VQ-VAE(Vector Quantized Variational Autoencoder,向量量化变分自编码器)是一种结合了自编码器和离散表示学习的方法,主要用于将连续的潜在空间映射为有限集合的离散向量(即“码本”中的向量)。其核心思想如下:
-
结构组成:
- 编码器(Encoder):将输入数据(如图片、音频、embedding等)编码为连续的潜在向量。
- 向量量化(Vector Quantization):将编码器输出的连续向量,查找最近的码本向量(codebook embedding),并用该离散向量替换原始输出,实现离散化。
- 解码器(Decoder):将离散化后的向量还原为原始数据。
-
训练目标:
- 重构损失:保证解码器输出与原始输入尽可能接近。
- 向量量化损失:鼓励编码器输出靠近码本中的某个向量。
- 承载损失(commitment loss):防止编码器输出频繁跳变,保证稳定性。
-
典型流程:
- 输入数据 → 编码器 → 连续潜在向量 → 向量量化(查找最近码本向量)→ 离散向量 → 解码器 → 重构输出。
-
向量量化过程详解:
- 编码器输出一个连续的潜在向量 ,然后在码本(codebook) 中查找与 欧氏距离最近的向量 ,即 。
- 用 替换 作为离散化后的表示,输入给解码器。
-
向量量化的梯度更新:
- 由于最近邻查找是不可微的,VQ-VAE 采用“直通估计器(Straight-Through Estimator, STE)”来实现反向传播:
- 前向传播时,编码器输出被替换为最近的码本向量。
- 反向传播时,梯度直接从解码器输出传递回编码器输入,跳过量化操作。
- 码本向量的更新则通过最小化 (sg 表示 stop-gradient)来实现,即只对码本参数求梯度,不对编码器参数求梯度。
- 同时引入 commitment loss ,鼓励编码器输出靠近被选中的码本向量。
- 由于最近邻查找是不可微的,VQ-VAE 采用“直通估计器(Straight-Through Estimator, STE)”来实现反向传播:
这种机制保证了模型可以端到端地训练,既能学习到高效的离散表示,又能保持训练过程的稳定性。
VQ-VAE 的提出为后续如 RQ-VAE 等模型的发展奠定了基础,尤其在需要将连续特征离散化为语义码的任务中表现突出。
但 VQ-VAE 的局限在于对连续特征的表达能力有限,因此 RQ-VAE 在其基础上引入了重参数化技巧,使模型能够同时建模离散语义码与连续特征。
RQ-VAE 详解#
RQ-VAE(Residual Quantized Variational Autoencoder,残差量化变分自编码器)是在 VQ-VAE 基础上的改进模型,旨在提升对复杂分布和连续特征的表达能力。其主要创新点和改进如下:
-
多级残差量化(Residual Quantization):
- RQ-VAE 不再只用一级码本对编码器输出进行量化,而是采用多级残差量化。即:
- 第一级用码本 对编码器输出 进行量化,得到 。
- 第二级用码本 对残差 进行量化,得到 。
- 依此类推,最终离散表示为 。
- 这种方式能更细致地逼近原始连续特征,提升表达能力。
- RQ-VAE 不再只用一级码本对编码器输出进行量化,而是采用多级残差量化。即:
-
连续与离散特征的结合:
- RQ-VAE 通过多级残差量化,使得每一级都能捕捉不同粒度的信息,既保留了离散语义码的优势,又能更好地拟合连续特征。
-
重参数化技巧:
- 在训练过程中,RQ-VAE 引入了重参数化技巧,使得量化过程对编码器参数可微分,进一步提升了模型的可训练性和稳定性。
-
优势与应用:
- RQ-VAE 能够生成更高质量、更具判别性的离散语义码,适用于多模态特征融合、推荐系统、生成建模等场景。
-
与 VQ-VAE 的对比:
- VQ-VAE 只能用单一离散码本近似连续特征,表达能力有限。
- RQ-VAE 通过多级残差量化和重参数化,显著提升了对复杂分布和连续特征的建模能力。
综上,RQ-VAE 通过多级残差量化和重参数化技巧,实现了离散与连续特征的有机结合,是 VQ-VAE 的重要升级。
明日再写代码,在云端环境中进行实验。已经有人提交评测了,得抓紧时间了。
8.14 实验记录#
补全了rqvae缺失的代码,跑起了实验,效果非常拉胯。
主要是rqvae训练速度尚可,baseline model效果则是非常糟糕。一个step的时间需要4分钟,而一个epoch则需要一千个step。根本就是不可接受的。
需要排查问题,加速训练过程,优化权重保存逻辑。
8.23 反思#
实验停了,这几天没干什么,感觉有些迷茫。需要重新理清思路,找回状态。
现在想清楚了,对于整个训练流程换了一种思路。
- 首先需要训练一个RQ-VAE模型,确保其能够有效地对输入数据进行编码和解码。
- 在RQ-VAE模型训练完成后,利用其生成的离散语义码作为新特征,加入到推荐系统的训练中。这个过程可以单独拿出来不需要和baseline模型训练一起进行,训练得到的权重需要放到USER_CACHE_PATH中,方便后续baseline模型训练调用;或者如果物品的品类有限,可以考虑将物品的Semantic IDs也放到USER_CACHE_PATH中。
- 通过这种方式,可以有效地缩小多模态模型与推荐模型之间的差距,提高推荐效果。
9.4 重启#
八月末忙着补考,补考完了还有个仓库的代码需要修改,当然中间也放松了几天,一直拖到现在。当务之急是抓紧时间做出成绩,基本上已经没有时间进行参数优化和更多的迭代了。
下面是这几天的记录#
| 日期 | 内容 |
|---|---|
| 9.7 | 时隔三十七天终于完成了baseline: Score: 0.0214127 NDCG@10: 0.0164562 HitRate@10: 0.0324451 |
| 9.8 | 以及直接用到mm_emb_id 82上的结果:Score: 0.0231574 NDCG@10: 0.0176182 HitRate@10: 0.0354865 |
| 9.9 | 完成了RQ-VAE的训练,同时向baseline训练中引入 |
| 9.10 | 测试9.9完成的工作,在mm_emb_id 81上进行测试Score: 0.0197788 NDCG@10: 0.0152141 HitRate@10: 0.0299388 效果不乐观 |
线上分享资料#
刚刚又翻看了一下比赛新闻以及小红书上比赛相关话题,发现有一些新的进展和动态,可能会对后续的工作有所启发。
1. 比赛新闻#
Angel平台&GPU虚拟化技术全解析|赛期进阶攻略第1期 ↗ 主要是介绍了Angel平台的使用方法和GPU虚拟化技术,帮助参赛者更好地利用平台资源进行模型训练和调优。
2. 小红书话题#
Ado#
- 数据中的序列是曝光序列(Action type 0是曝光,1是点击)需要预测的是点击序列
- 扩充负样本,随机采样即可,通过in batch negative计算loss
-
方法 score baseline 0.025 baseline + triple loss 0.028 增加infonce loss,去掉bce 0.048 增加epoch到5 0.051 重构训练,调整参数和结构 0.067-0.068 - infonce需要让正样本相似度比负样本高,计算正样本相似度:seq_embs和pos_embs的点积;负样本选择in batch negative,选择batch内所有的neg_embs但基于曝光偏差问题不包括其它sample的pos_embs,整体neg全为随机负样本。
- 对padding item做mask,不计算其loss
- 正样本位置在拼接后为0,即交叉熵label为0
- 温度系数按经验为0.07
-
方法 score test修复最后一个item被截断 0.077 加入时间特征 0.084 scaling up至128+hstu+全量 0.084-0.094 - baseline加prenorm,rmsnorm,调整transformer参数layer4,head4,dim64(早期调整)
唐今里#
-
方法描述 指标值 baseline 0.025 baseline + BCE + 负采样 0.035 BCE换InfoNCE 0.045 模型参数scale up 0.053 分离user和item的数据处理和读取,修改多进程数据加载,PyTorch重写faiss检索,单卡训练20min/epoch,推理10min - 修改Embedding初始化 0.057 增加负样本数量 0.059 增加更多LayerNorm 0.061 Transformer改成pre-norm结构 0.064 降低temperature 0.066 增加dropout & epoch数从3减少到2 0.069 - 训练加速思路:
- 推理加速思路:
 将faiss替换成faiss-gpu或者pytorch实现,单卡推理10min
将faiss替换成faiss-gpu或者pytorch实现,单卡推理10min - baseline测试阶段的数据构造有问题,只取seq[:-1]不合理
- InfoNCE还可以优化改进,核心是提升召回能力
- 模型参数scale up 提升显著
- user 和 item embedding初始化,zero init 可以提供不少涨幅
AKFrames#
这是9.12补充。
- baseline的结构上加入layernorm和dropout,变成四连,然后做残差变为三层mlp,这个掉点千7(logits在1000步内迅速从9跌到-3,并开始持续震荡,目前还没研究明白是因为什么,同时伴随正样本相似度也下降,感觉模型把正负样本都推开导致的)
- 线下和线上的一些分析,把苗头指向layernorm和dropout,与g老师的一通交流让我选择通过指标来观测模型,而不是靠瞎猜。线下的实验指向layernorm,线上的实验在更大数据集上指向了dropout,通过对logits的分析,促使我去掉了dropout,结构变为堆叠两层。logits下降正常,最后验证集loss从2.8降低到2.75。但是测试集掉千一,因为无法得到测试集gt做进一步分析,于是放弃这条路。
- 两线性夹激活,logits上升,valid loss轻微上升,但是正负相似度的差距比之前高,没有机会测,判断为寄。
- 不同维度两线性夹激活,先到512,再到256,取代原本的两层256,模型效果从验证集loss来看甚至低一些,logits上升,测评有限的情况下没测,奥卡姆剃刀原则让我放弃这种复杂结构。这一版看起来是比上面是要好的,正负样本相似度也拉开了。
- 转战dcn,因为觉得走加深走不通,开始走交叉,这一步是做特征的n+1阶交叉,可惜loss上升,logits也变得古怪,大约5000步才降低到0。最后val loss略微增加。没测。
- 在推理时直接统计测试集的流行度分布,把item分成四部分(我随意分的,还有更细致的做法),热门物品前10%,40%普通物品,50%冷门物品,以及冷启动item,这边统计大概1/6的冷启动item。
现在需要消化吸收这些信息,结合自己的实验结果进行分析和改进。
实际上现在需要进行艰难的抉择了,是继续使用BaselineModel还是使用HSTU模型。
9.11 HSTU模型#
很遗憾昨天对baseline进行魔改+scale up,训练倒是可以跑通,但是infer超时,每次都是在构建HNSW索引时卡住,尝试了多种方法都无法解决这个问题。
今天尝试使用HSTU,祝我好运吧。
9.12 💊#
魔改baseline仍然无法评测,准备放弃。
至于HSTU,也是获得了一个幽默至极的结果:Score: 0.0117385 NDCG@10: 0.0088995 HitRate@10: 0.0180577,训练时这些指标看着都非常好,但是一上测试就拉胯成这样。
9.13 and 14#
完结,名次大概1k+了,完全失败。
经验教训#
比赛本身还是很有趣的,可惜我是在最后一周才意识到。
惨败实际上还是本人能力有限所致。
平台比较难用,调试困难导致迭代困难。
参加比赛一定要利用好每一分每一秒。